Imitation Learning with Franka Emika Panda
How to transfer the imitation learning techniques to a more complex robotic arm like Franka Emika Panda.
Overview
In previous work, we demonstrated how robotic arms can learn from human demonstrations through Action Chunking Transformer(ACT). In this part, we demonsrate how we shift to Franka emika panda .
1. Data Collection
The first step is collecting high-quality demonstration data from human teleoperation.
Dataset Format
We use the same LeRobot dataset format, which stores episodes as Parquet files and mp4 for front and wrist camera observation.
# Robot Joint States (7-DOF)
- "eef_x"
- "eef_y"
- "eef_z"
- "eef_quat_x"
- "eef_quat_y"
- "eef_quat_z"
- "eef_quat_w"
- "gripper_width"
# Camera Observations
- "observation.images.front"
- "observation.images.wrist_front"
- "observation.images.wrist_rear"
LeRobot dataset structure with end effector positions, quaternions and camera observations
Control Method
Human demonstrations are collected via teleoperation using a leader-follower setup, where the operator controls a leader arm and the follower arm mimics the movements.
Detail: We utilize GELLO project to mimic the similar method we use on koch robot in data collection. We are using joint impedance control for Franka Emika Panda by Franka ROS and using leading arm's joint states to control the follower arm in a leader-follower teleoperation setup.
Leader-follower teleoperation for data collection
Previous Control Method
Previously, we employed Vision Pro to control the Franka Emika Panda. Vision pro detects the operator's hand to utilize relative movement to control robot relative end effector movement.
However, we realized that vision pro control is not intuitve for this Franka Emika panda setup, it might be useful in bimanual robots.
Detail: we are inspired by Unitree Robotic Avp_teleoperate which also uses vision pro for data collection. We are using the same method in our early stage of data collection before we switch to leader-follower teleoperation method.
Vision Pro controlled pick-and-place demonstration
2. Model Training
After collecting demonstration data, we train imitation learning models to predict robot actions from visual observations.
ACT (Action Chunking Transformer)
A pure imitation learning approach that predicts action sequences("chunks") rather than single actions . It uses a transformer encoder-decoder architecture with a CVAE (Conditional Variational Autoencoder) for modeling action distributions.
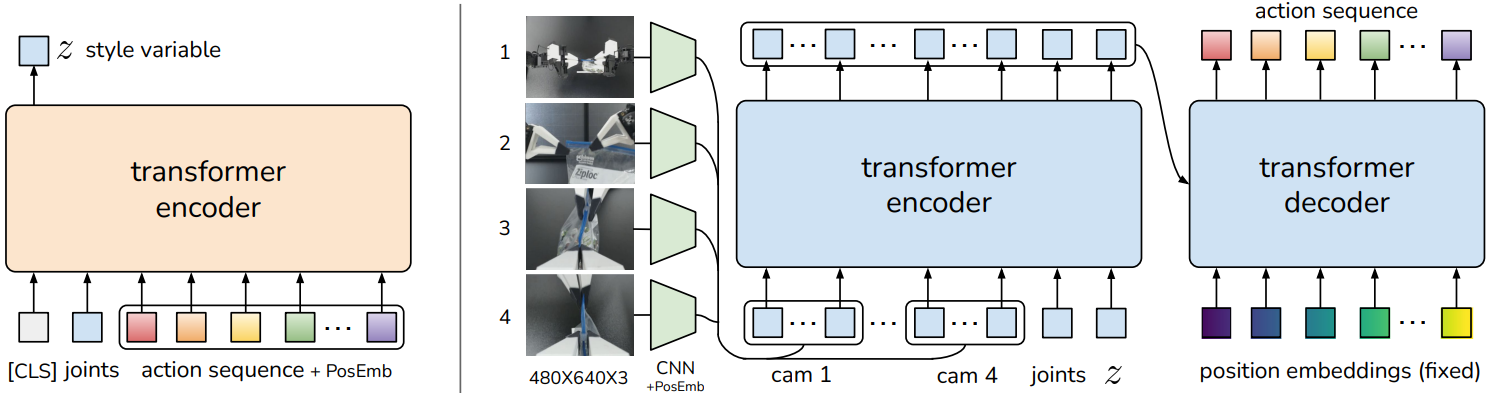
ACT Architecture (Source: ACT Paper)
✅ Strengths
- • Fast training (no VLM backbone)
- • Lightweight (~25M parameters)
- • Good for single-task learning
⚠️ Limitations
- • No language understanding
- • Requires task-specific training
- • Limited generalization
3. Deployment
The trained model is deployed on the robot for real-time inference and autonomous task execution.
Real-time Inference
The model runs at ~10Hz, predicting action chunks that are executed by the robot controller in real-time.