VLAs with low-cost robotic arm
Imagine a robotic arm that can learn to perform tasks just by watching human demonstrations and reading instruction!
Overview
In previous work, we demonstrate how we use Action Chunking Transformer(ACT) to enable robotic arms to learn from human demonstrations,but language can not be directly used.
This project demonstrates how robotic arms can learn using Visual Language Action (VLA) models like SmolVLA, that we can use language instructions with.
1. Data Collection
In data collection, we use the same setup as the previous projects, but we also collect language instructions along with the demonstrations.
Dataset Format
We use the LeRobot dataset format, which stores episodes as Parquet files containing observation(following robot joint states) , and action(leading arm's joint states) and mp4 for top and front camera observation.
# Robot Joint States (6-DOF)
- "shoulder_pan.pos"
- "shoulder_lift.pos"
- "elbow_flex.pos"
- "wrist_flex.pos"
- "wrist_roll.pos"
- "gripper.pos"
# Camera Observations
- "observation.images.front"
- "observation.images.top"
LeRobot dataset structure with joint positions and camera observations
Control Method
Human demonstrations are collected via teleoperation using a leader-follower setup, where the operator controls a leader arm and the follower arm mimics the movements.
Leader-follower teleoperation for data collection
2. Model Training
After collecting demonstration data, we train VLA model(SmolVLA) to predict robot actions from visual observations and language instructions.
SmolVLA (Small Vision-Language Action Model)
Unlike common VLA models that use large vision-language backbones, SmolVLA is a lightweight model designed for fast training and inference on robotic arms.
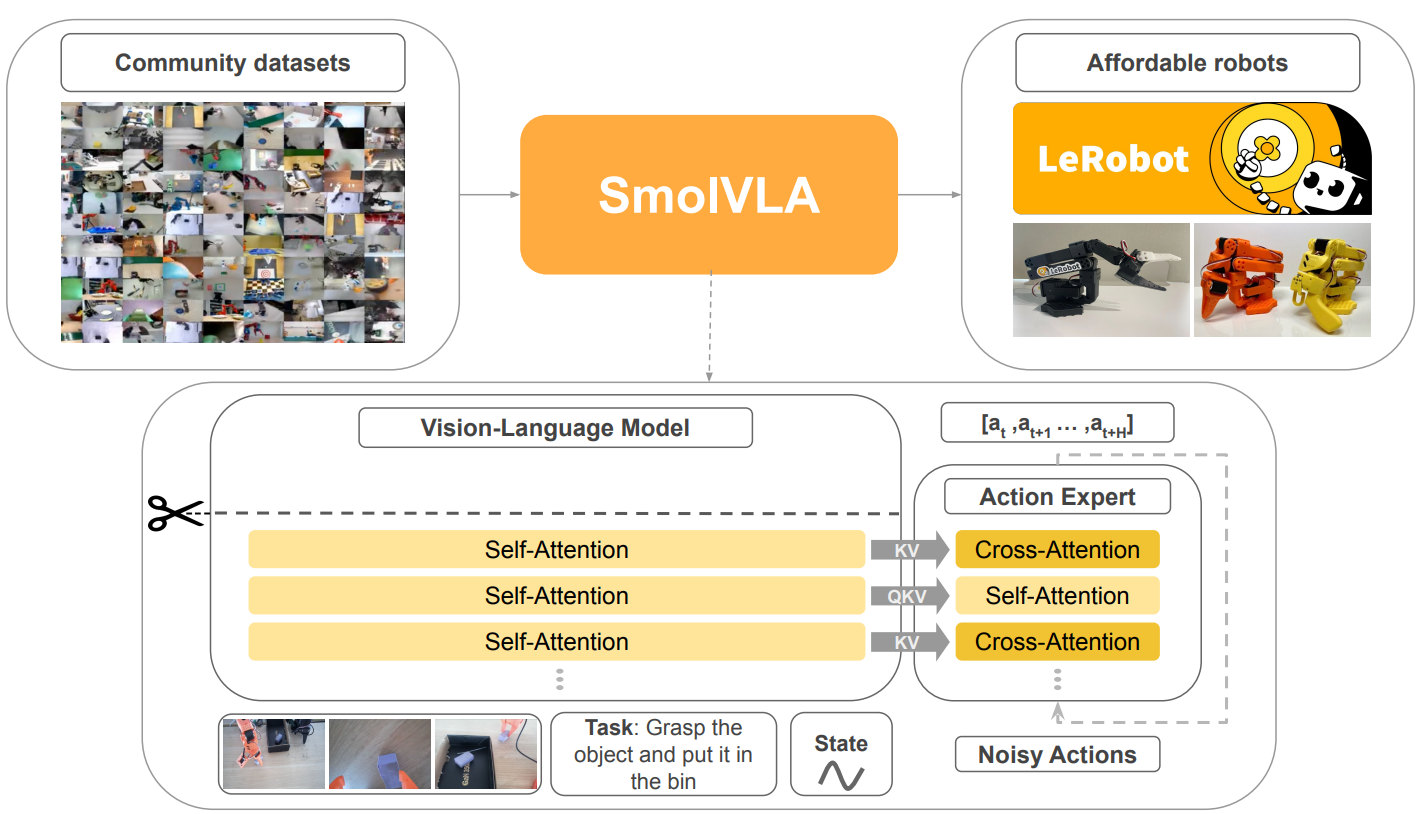
SmolVLA Architecture (Source: SmolVLA Paper)
✅ Strengths
- • Fast training (Lightweight architecture)
- • Resource constraint (efficient inference)
- • Smooth trajectory generation(SA interleaves CA)
⚠️ Limitations
- • Poor zero-shot generalization
- • Not optimized for cross-embodiment transfer
- • Limited generalization
3. Deployment
The trained model is deployed on the robot for real-time inference and autonomous task execution.
Real-time Inference
The model runs at ~30Hz, predicting actions that are executed by the robot controller in real-time.
Autonomous real-time task switching execution after 100 episodes for each task after training Dataset
Autonomous real-time task switching execution after 60 episodes for each task after training Dataset