Model Interpretability on VLA Models
Open up the black box of VLA models and understand how they make decisions in robotic tasks.
Overview
In previous work, we demonstrated how robotic arms can learn from human demonstrations through demonstrations, but how do these VLA models actually make decisions?
Interpretability Methods
We apply various interpretability techniques to analyze the inner workings of VLA models, including:
- Attention Visualization: Visualize attention weights to see which parts of the input the model focuses on.
- FFN Analysis: Analyze the feed-forward networks to understand their contribution to the model's decisions.
Attention Visualization
By visualizing the attention weights, we can see which parts of the visual input and language instructions the model is focusing on when making decisions.
In the example below, we will demonstrate the experimental results of attention visualization on VLM part "self attention block" of SmolVLA and also "cross attention" block in action expert module.
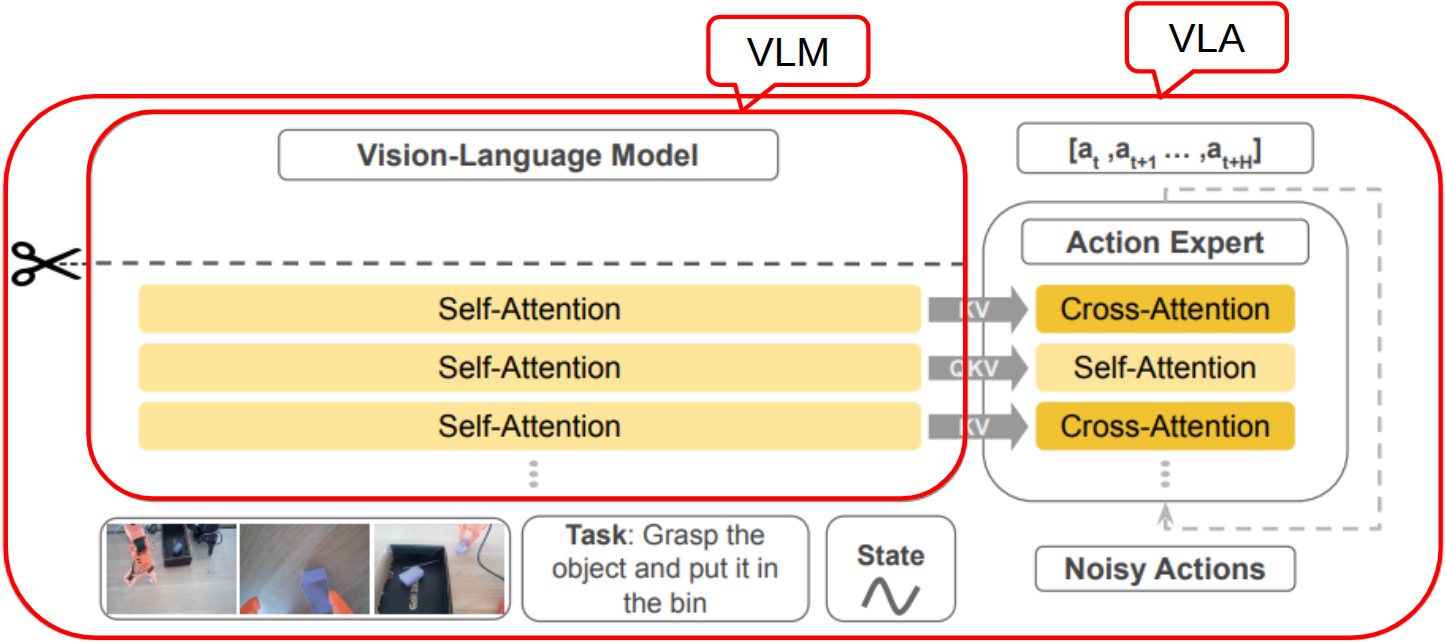
SmolVLA architecture Paper
VLM Attention Heatmap Results
Attention heatmaps from the vision-language model showing how the model attends to different regions of the image and language tokens during processing.
We can clearly see the attention is noisy in environment, because the VLM does not take joint observations, and VLM is unfrzoen in default training(Rely on its pre-trained understanding)
Action Expert Attention Heatmap Results
Attention heatmaps from the last cross attention block in the action expert module showing how the model attends to different features when making decisions.
Attention is more focused in the action expert module, cause it is closer to the decision-making process, but it is still noisy
Unfrozen VLM Attention Heatmap Results
Unfrozen VLM can adapt its attention based on the robot's joint observations and task-specific data, which can lead to more focused attention on relevant features in the environment.
The Denser and more focused attention heatmap indicates that the robot is learning to attend to the most relevant parts of the input for decision-making, which can lead to improved performance and better generalization in robotic tasks.
Real-time attention visualization for the unfrozen VLM
FFN Analysis
Inspired by the work of Mechanistic interpretability for steering vision-language-action models, we analyze the feed-forward networks (FFNs) in the VLA model and identify specific semantic neurons that curry meaning as "High","Low","Fast","Slow"
By activating these neurons, we can control the robot to execute different trajectories, such as high or low trajectories, fast or slow trajectories.
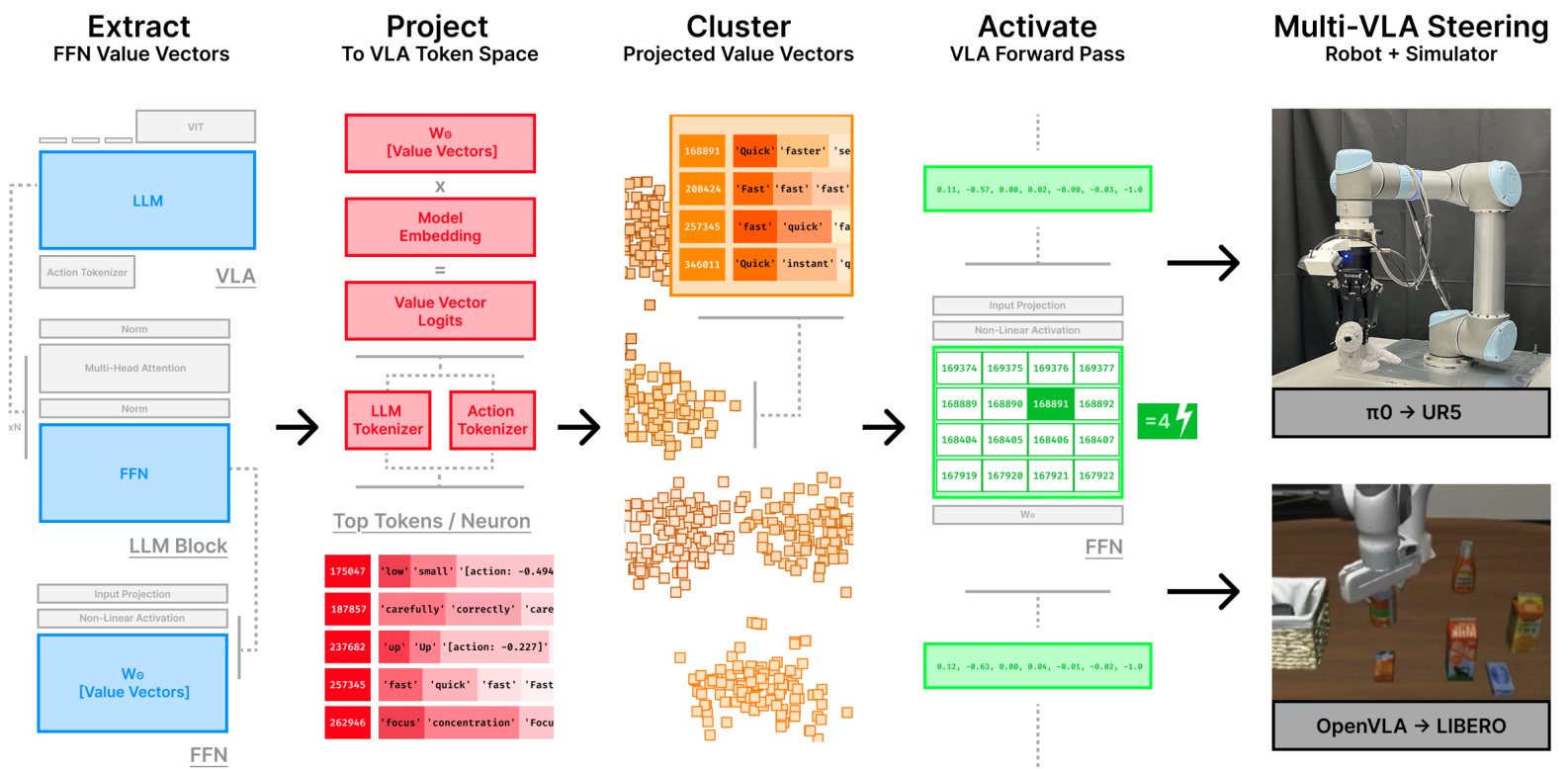
Mechanistic Interpretability Analysis Paper
FFN Experiment Setup
High trajectory demonstration
Low trajectory demonstration
We collect high and low trajectory demonstrations in dataset, and with the same prompt description.
We will find semantic neurons in the FFN that can distinguish high and low trajectories, and by activating these neurons, we can control the robot to execute high or low trajectories.
FFN Experiment Result
By extracting the value vector from VLM's FFN, and then project to VLA token space, we can find neurons that have semantic meaning as "High" and "Low". By activating these neurons, we can control the robot to execute high or low trajectories.
High trajectory evaluation Eval Dataset
Low trajectory evaluation Eval Dataset
FFN Experiment Result(EEF height)
We pick the trajectory segment where the robot is lifting up the object, and we can see that by activating "High" neuron, the end-effector height is higher than activating "Low" neuron.
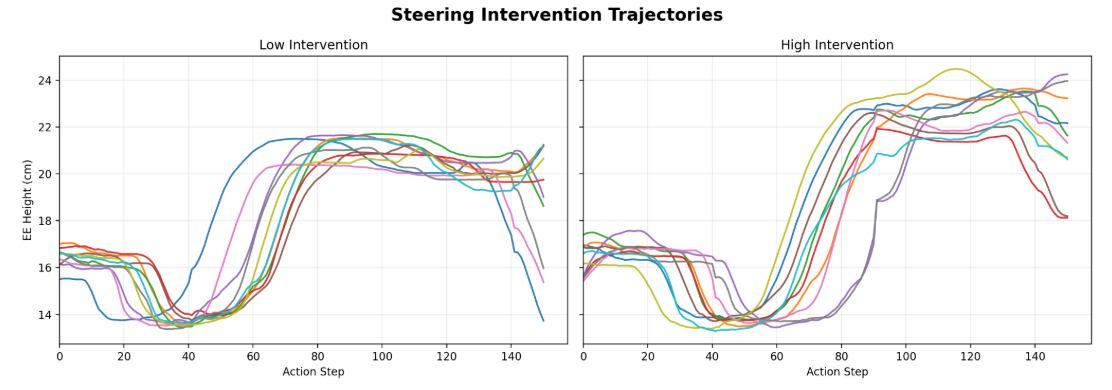
High vs. Low eef height comparison in 10 rollouts